Synthetic data generation using large language models (LLMs) offers a powerful solution to a commonly faced problem: the availability of high-quality, diverse, and privacy-compliant data. This could be used in a number of scenarios such as training a data science machine learning model (SVMs, decision trees, KNN's), finetuning a different GPT model on the data, as a solution to the coldstart problem, helping build compelling demos/apps with realistic data, scenario testing etc.
There are a number of key drivers which may see you wanting to leverage synthetic data.
Human data may have privacy restrictions and/or identifiable data within it which we do not want to be used.
Synthetic data can be much more structured and therefore easier to manipulate than real data.
In domains where data is sparse or data of certain categories is sparse we may want to augment the data.
When dealing with imbalanced datasets or datasets which lack diversity, we may want to create data to improve the richness of our datasets.
Unlike traditional data augmentation or manual data creation methods, using LLMs allows for the generation of rich, nuanced, and contextually relevant datasets that can significantly enhance it's usefulness to enterprises and developers.
We split this tutorial into 2 parts. In this cookbook, we will have the following agenda:
CSV with a structured prompt
CSV with a Python program
Multitable CSV with a python program
Simply creating textual data
Dealing with imbalanced or non-diverse textual data
while in part 2, we will look at prompting strategies for getting better textual data.
The last two in particular are useful for creating synthetic data to finetune another GPT model. For example using higher quality data produced by gpt-4 to finetune the cheaper and quicker gpt-3.5 for improved performance while reducing costs.
from openai import OpenAIimport reimport numpy as npimport pandas as pdfrom sklearn.cluster import KMeansimport matplotlib.pyplot as pltimport jsonimport matplotlib
Here we create data in the simplest way. You can quickly generate data by addressing 3 key points: telling it the format of the data (CSV), the schema, and useful information regarding how columns relate (the LLM will be able to deduce this from the column names but a helping hand will improve performance).
datagen_model ="gpt-4-0125-preview"question ="""Create a CSV file with 10 rows of housing data.Each row should include the following fields: - id (incrementing integer starting at 1) - house size (m^2) - house price - location - number of bedroomsMake sure that the numbers make sense (i.e. more rooms is usually bigger size, more expensive locations increase price. more size is usually higher price etc. make sure all the numbers make sense). Also only respond with the CSV."""response = client.chat.completions.create(model=datagen_model,messages=[ {"role": "system", "content": "You are a helpful assistant designed to generate synthetic data."}, {"role": "user", "content": question} ])res = response.choices[0].message.contentprint(res)
The issue with generating data directly is we are limited in the amount of data we can generate because of the context. Instead what we can do is ask the LLM to generate a python program to generate the synthetic data. This allows us to scale to much more data while also providing us a view into how the data was generated by inspecting the python program.
This would then let us edit the python program as we desire while giving us a good basis to start from.
question ="""Create a Python program to generate 100 rows of housing data.I want you to at the end of it output a pandas dataframe with 100 rows of data.Each row should include the following fields: - id (incrementing integer starting at 1) - house size (m^2) - house price - location - number of bedroomsMake sure that the numbers make sense (i.e. more rooms is usually bigger size, more expensive locations increase price. more size is usually higher price etc. make sure all the numbers make sense)."""response = client.chat.completions.create(model=datagen_model,messages=[ {"role": "system", "content": "You are a helpful assistant designed to generate synthetic data."}, {"role": "user", "content": question} ])res = response.choices[0].message.contentprint(res)
To generate synthetic housing data and output it as a Pandas DataFrame, we can use Python with the `pandas` and `numpy` libraries. Below is a script that creates 100 rows of housing data considering the prescribed logic for house size, price, and number of bedrooms. It also takes into account the impact of location on house price.
First, ensure you have pandas and numpy installed. You can install them via pip if you haven't already:
```
pip install pandas numpy
```
The script:
```python
import pandas as pd
import numpy as np
# Seed for reproducibility
np.random.seed(42)
# Initialize the lists
ids = list(range(1, 101))
sizes = np.random.normal(150, 50, 100).astype(int) # House sizes with a mean of 150 m^2 and a std of 50
bedrooms = np.random.choice([1, 2, 3, 4, 5], 100) # Number of bedrooms
locations = np.random.choice(['Downtown', 'Suburb', 'Countryside'], 100, p=[0.4, 0.4, 0.2]) # Location of houses with a preferential distribution
# Prices will be influenced by location, size, and bedrooms. This part is simplistic and can be made more complex.
base_price = 100000 # Base price
price_per_m2 = 1000 # Base price per m^2
extra_per_bedroom = 5000 # Extra cost per additional bedroom
prices = []
for i in range(100):
base_location_multiplier = 1.5 if locations[i] == 'Downtown' else 1.2 if locations[i] == 'Suburb' else 1
location_multiplier = base_location_multiplier * (1 + (sizes[i] / 1000)) # More expensive if bigger, especially downtown
price = base_price + (sizes[i] * price_per_m2) + (bedrooms[i] * extra_per_bedroom)
prices.append(int(price * location_multiplier))
# Create DataFrame
data = {
'id': ids,
'house size (m^2)': sizes,
'number of bedrooms': bedrooms,
'location': locations,
'house price': prices
}
df = pd.DataFrame(data)
print(df)
```
This program initializes with a seed for reproducibility while creating randomized but plausible data for housing. The sizes are normally distributed around a mean value, and bedrooms are chosen from a set number. The pricing logic uses base values plus increases according to size, bedroom count, and a location multiplier, with downtown locations inflating prices more than suburbs or countryside locations. Adjustments are simplistic for the purpose of example and can be refined for more nuanced simulations.
We need to make sure to parse the output of this appropriately as often there may be surrounding text to the python code. We can also explicitly ask it to state all assumptions it made about the data it's generating, however in this circumstance it told us that automatically.
For more complex relationships however we need to make sure to specify a few more characteristics.
To create multiple different datasets which relate to each other (for example housing, location, house type), as before we would need to specify the format, schema and useful information. However, the useful information required to get good performance is higher now. It's case-specific but a good amount of things to describe would be how the datasets relate to each other, addressing the size of the datasets in relation to one another, making sure foreign and primary keys are made appropriately and ideally using previously generated datasets to populate new ones so the actual data values match where necessary.
question ="""Create a Python program to generate 3 different pandas dataframes.1. Housing dataI want 100 rows. Each row should include the following fields: - id (incrementing integer starting at 1) - house size (m^2) - house price - location - number of bedrooms - house type + any relevant foreign keys2. LocationEach row should include the following fields: - id (incrementing integer starting at 1) - country - city - population - area (m^2) + any relevant foreign keys 3. House types - id (incrementing integer starting at 1) - house type - average house type price - number of houses + any relevant foreign keysMake sure that the numbers make sense (i.e. more rooms is usually bigger size, more expensive locations increase price. more size is usually higher price etc. make sure all the numbers make sense).Make sure that the dataframe generally follow common sense checks, e.g. the size of the dataframes make sense in comparison with one another.Make sure the foreign keys match up and you can use previously generated dataframes when creating each consecutive dataframes.You can use the previously generated dataframe to generate the next dataframe."""response = client.chat.completions.create(model=datagen_model,messages=[ {"role": "system", "content": "You are a helpful assistant designed to generate synthetic data."}, {"role": "user", "content": question} ])res = response.choices[0].message.contentprint(res)
To create a Python program generating three Pandas DataFrames as described, I'll lay out a step-by-step process considering the relationships between the different types of data:
1. Install pandas if you haven't yet: `pip install pandas`
2. Import pandas and generate each DataFrame. I'll make some assumptions for the synthetic data to keep it relatively simple.
Let's start coding:
```python
import pandas as pd
import numpy as np
# Generating Location DataFrame
np.random.seed(42) # For reproducibility
location_data = {
'id': range(1, 11), # Assuming 10 unique locations
'country': ['CountryA'] * 5 + ['CountryB'] * 5,
'city': ['City' + str(i) for i in range(1, 11)],
'population': np.random.randint(100000, 1000000, size=10),
'area': np.random.randint(500, 20000, size=10),
}
locations_df = pd.DataFrame(location_data)
# Generating House Types DataFrame
house_types_data = {
'id': range(1, 5), # Assuming 4 unique house types
'house type': ['Villa', 'Apartment', 'Townhouse', 'Bungalow'],
'average house type price': [300000, 200000, 250000, 220000], # Just arbitrary prices
'number of houses': [25, 50, 15, 10], # Total = 100 houses, matching the housing data requirement
}
house_types_df = pd.DataFrame(house_types_data)
# Generating Housing Data
housing_data = {
'id': range(1, 101),
'house size': np.random.randint(50, 500, size=100),
'house price': [], # To be calculated based on size, location, etc.
'location_id': np.random.choice(locations_df['id'], size=100),
'number of bedrooms': np.random.randint(1, 6, size=100),
'house_type_id': np.random.choice(house_types_df['id'], size=100),
}
# Simple model to calculate house price based on size, type, and a base price from the location's median
base_prices = locations_df['population'] / 100000 # Simplified assumption: more populous => more expensive
housing_data['house price'] = [
(1200 * size) + (house_types_df.loc[type_id - 1, 'average house type price']) + (base_prices[loc_id - 1] * 1000)
for size, type_id, loc_id
in zip(housing_data['house size'], housing_data['house_type_id'], housing_data['location_id'])
]
housing_df = pd.DataFrame(housing_data)
# Display the first few rows of each DataFrame
print(locations_df.head())
print(house_types_df.head())
print(housing_df.head())
```
Notes:
- This script assumes 10 unique locations and 4 house types for simplicity.
- House prices are arbitrarily calculated using the house size, type, and a base price influenced by the location's population. Reality would require a more complex model.
- `numpy.random.randint` is used to generate integer values. Similarly, `numpy.random.choice` is used to randomly assign locations and house types to each house, demonstrating a form of foreign key relationship.
- For simplicity, foreign keys are represented by corresponding ID fields (e.g., `location_id` in the housing data references the `id` in the location data).
This simple synthetic data generation strategy illustrates creating related data sets with Python and pandas. The synthetic data should make general sense within the constraints provided, but keep in mind that for more complex or realistic data modeling, you'd need to incorporate more detailed rules and possibly real-world data.
Here we take a first look at creating textual data. This can be used to finetune another GPT model for example. In this case we imagine ourselves a retailer trying to streamline the process of creating descriptions for items they are selling. We again need to specify the format of the data, in particular in this case we want one which is easy to parse as an output.
The example we consider below is one in which we want to create input output training pairs for GPT model to finetune on. We will have the products' name and the category it belongs to as input and the output will be a description.
Specifying the structure of the output explicitly and giving commands to not deviate from this help enforce the output structure. You can run this in a loop and append the data to generate more synthetic data. Again, as before we will need to parse the data well so that our code further downstream does not break.
output_string =""for i inrange(3): question =f""" I am creating input output training pairs to fine tune my gpt model. The usecase is a retailer generating a description for a product from a product catalogue. I want the input to be product name and category (to which the product belongs to) and output to be description. The format should be of the form: 1. Input: product_name, category Output: description 2. Input: product_name, category Output: description Do not add any extra characters around that formatting as it will make the output parsing break. Create as many training pairs as possible. """ response = client.chat.completions.create(model=datagen_model,messages=[ {"role": "system", "content": "You are a helpful assistant designed to generate synthetic data."}, {"role": "user", "content": question} ] ) res = response.choices[0].message.content output_string += res +"\n"+"\n"print(output_string[:1000]) #displaying truncated response
1.
Input: Northface Waterproof Jacket, Clothing
Output: Stay dry and stylish with the Northface Waterproof Jacket. Perfect for outdoor adventurers and city dwellers alike, this jacket combines cutting-edge waterproof technology with a sleek, modern design. Ideal for unpredictable weather, it ensures you're prepared for anything Mother Nature throws your way.
2.
Input: Apple iPhone 12, Electronics
Output: Experience the next level of innovation with the Apple iPhone 12. Featuring a stunning Super Retina XDR display, a powerful A14 Bionic chip, and advanced dual-camera system, this phone is designed to push the boundaries of what's possible. With 5G capability for super-fast downloads and high-quality streaming, it's the perfect device for tech enthusiasts.
3.
Input: Adidas Ultraboost Sneakers, Footwear
Output: Revolutionize your running experience with Adidas Ultraboost Sneakers. Engineered for long-lasting comfort and superior performance, these sneakers feature the innovative Boost
Note: the above output is truncated. And now we can parse it as below to get a list of products, categories and their descriptions. For example, let's take a look at the products it's generated.
#regex to parse datapattern = re.compile(r'Input:\s*(.+?),\s*(.+?)\nOutput:\s*(.+?)(?=\n\n|\Z)', re.DOTALL)matches = pattern.findall(output_string)products = []categories = []descriptions = []for match in matches: product, category, description = match products.append(product.strip()) categories.append(category.strip()) descriptions.append(description.strip())products
['Northface Waterproof Jacket',
'Apple iPhone 12',
'Adidas Ultraboost Sneakers',
'LEGO Star Wars Millennium Falcon',
'Vitamix Professional Series 750 Blender',
'Panasonic Lumix GH5 Camera',
'Moleskine Classic Notebook',
'Bodum French Press Coffee Maker',
'Classic White Sneakers',
'Multi-Purpose Blender',
'Eco-Friendly Yoga Mat',
'Organic Green Tea',
'Smart LED Light Bulb',
'Waterproof Hiking Boots',
'Bamboo Toothbrush',
'Modern Minimalist Floor Lamp',
'Classic Leather Office Chair',
'Stainless Steel French Press',
'Eco-Friendly Bamboo Cutting Board',
'Ultimate Gaming Laptop',
'Waterproof Hiking Boots',
'Compact Travel Umbrella',
"Professional Chef's Knife"]
Some of the most important aspects of generating high-quality synthetic data are accuracy (does the data make sense), consistency (are two separate data points for the same input roughly the same) and diversity (making sure our data distribution matches as much of the distribution that exists in production).
To increase the diversity of our data, we start first by clustering the data. This will provide us information about which clusters are underrepresented (imbalanced dataset) or which data is not addressed at all (widening the data distribution). Then, we will either suggest new clusters (using self-reflection type call from GPT) or ask the next iteration of our synthetic generation calls to explicitly target the underrepresented clusters.
We can then recursively run this generation and analysis of cluster loop to automate generating diverse synthetic data.
For demonstrative purposes, we explicitly prompt the LLM to generate information about 4 different topical areas: vehicle, clothing, toiletries, food. We will then cluster the data and see if it managed to find these 4 topic areas.
output_string =""for i inrange(3): question =f""" I am creating input output training pairs to fine tune my gpt model. I want the input to be product name and category and output to be description. the category should be things like: mobile phones, shoes, headphones, laptop, electronic toothbrush, etc. and also more importantly the categories should come under 4 main topics: vehicle, clothing, toiletries, food) After the number of each example also state the topic area. The format should be of the form: 1. topic_area Input: product_name, category Output: description Do not add any extra characters around that formatting as it will make the output parsing break. Here are some helpful examples so you get the style of output correct. 1) clothing Input: "Shoe Name, Shoes" Output: "Experience unparalleled comfort. These shoes feature a blend of modern style and the traditional superior cushioning, perfect for those always on the move." """ response = client.chat.completions.create(model="gpt-4",messages=[ {"role": "system", "content": "You are a helpful assistant designed to generate synthetic data."}, {"role": "user", "content": question} ] ) res = response.choices[0].message.content output_string += res +"\n"+"\n"print(output_string[:1000]) #displaying truncated response
2) toiletries
Input: "Toothbrush X5+, Electronic toothbrush"
Output: "Experience a superior cleanse with the Toothbrush X5+. It comes equipped with an advanced sonic technology that guarantees a gentle yet effective clean every time."
3) vehicle
Input: "Pegasus Pro 300, Motorcycle"
Output: "Dominate the road with the stylish Pegasus Pro 300. This motorcycle guarantees a powerful, efficient, and thrilling performance on every ride."
4) food
Input: "Tasty Delight Instant Noodles, Instant food"
Output: "Tasty Delight Instant Noodles offer a quick, delicious meal ready in minutes. The perfect solution for those stepping up their cooking game."
5) clothing
Input: "UltraSport Men's Running Jacket, Sportswear"
Output: "UltraSport Men's Running Jacket combines functionality and style. The breathable material allows for comfortable workouts, even in colder weather."
6) toiletries
Input: "FreshBliss Shower Gel, Bath and body"
Output: "Indulge in luxury every morning with the FreshBliss Showe
Note: The above output is truncated. In the example above, we would explicitly include the topic area as part of the response per example as it helps condition the proceeding output and tends to give better performance. We can also give it an actual example of what the output should look like so it gets the right idea of style of output but also to help enforce structure.
We will now cluster the data to analyze it. We will use K-means clustering to segregate the data. An important parameter of K-means to set is K, the number of clusters.
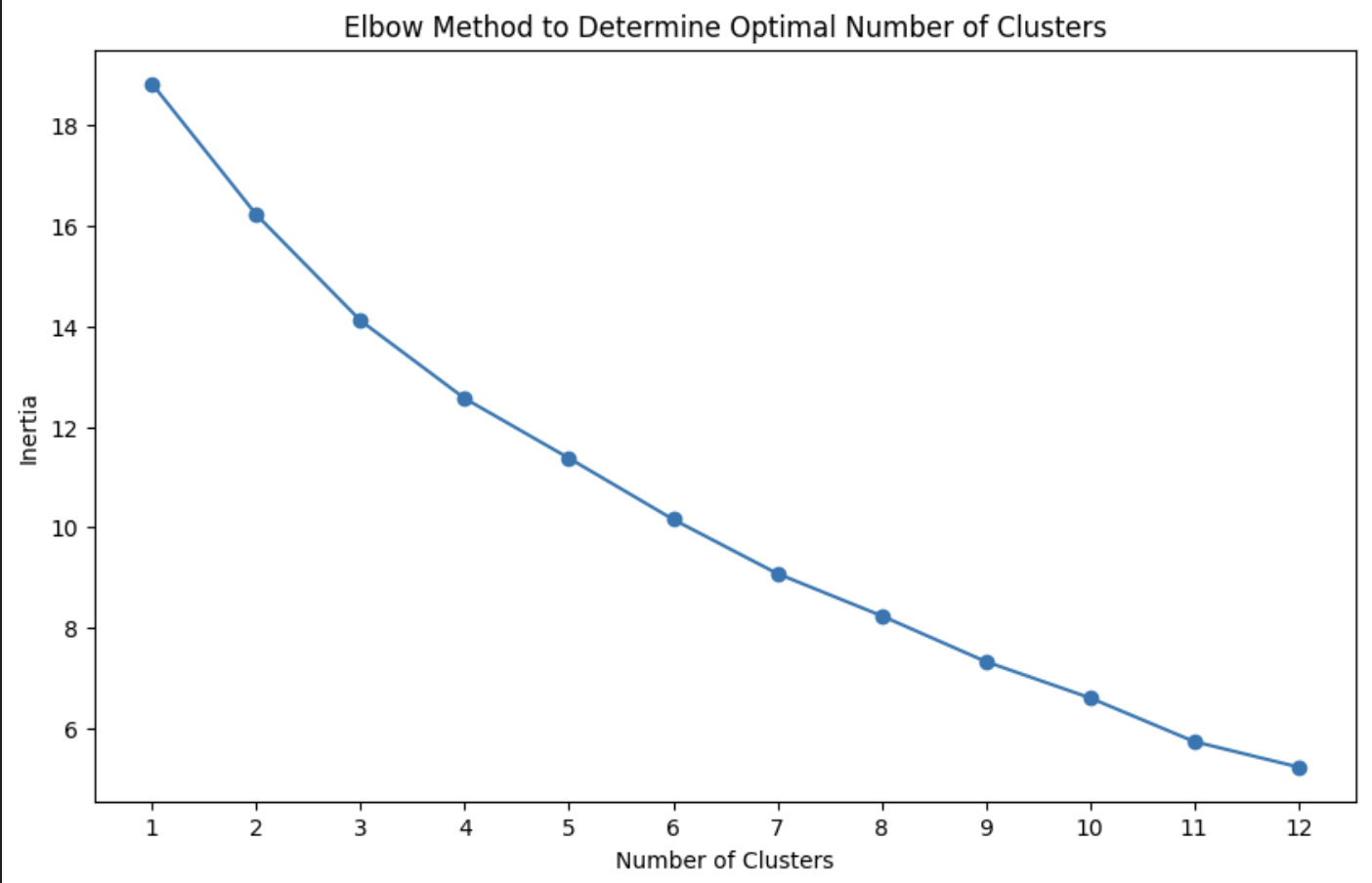
We know that there should be 4 cluster (4 topics) since we specified this in prompt: vehicle, electronics, clothing, food. However in general for our data, we do not know the number of clusters that exist. Therefore we will use the elbow method to find the optimal number of clusters.
In the elbow method, we iterate through a range of different K's, each time storing the inertia. The inertia measures the sum of the squared distances between each point in a cluster and the centroid of that cluster thus telling us how well-separated and dense each cluster is. If we plot K against the inertia, we are able to see how the inertia drops and where the drop in inertia is least rapid (often making an elbow shape) we can set our optimal number of clusters. You can read into more depth about the elbow method here.
First let's store our data into a pandas dataframe for ease of analysis
data = {'Product': products,'Category': categories,'Description': descriptions}df = pd.DataFrame(data)
Next let us embed our data as the embeddings is what we will cluster since they should be close to each other in vector space if they are similar.
# Determine the optimal number of clusters using the elbow methodinertias = []range_of_clusters =range(1, 13) # Adjust the range as necessaryfor n_clusters in range_of_clusters: kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42, n_init=10) kmeans.fit(matrix) inertias.append(kmeans.inertia_)
This will output a chart for us in which we have to visually tell where the optimal cluster point is. We can see below that we see a gradual decrease of inertia rather than a sharp elbow but the point of steepest decrease appears to occur around 3, 4 or 5 clusters which lines up with our expectations given our prompt.
# Plotting the elbow plotplt.figure(figsize=(10, 6))plt.plot(range_of_clusters, inertias, '-o')plt.title('Elbow Method to Determine Optimal Number of Clusters')plt.xlabel('Number of Clusters')plt.ylabel('Inertia')plt.xticks(range_of_clusters)plt.show()
For demonstration purposes we will pick 5 as the optimal cluster number to show it doesn't matter exactly where we pick it as long as we are approximately right. There are numerous correct ways to categorize data. We also store which cluster each data point belongs to.
We will analyze the cluster data now. There are two separate things we will look to address. 1. imbalanced data, 2. Expanding the data distribution.
First for imbalanced data we count the number of examples in each cluster. Then we select a few examples from each cluster at random and ask the LLM what topics these map to.
We can see the topics found here:
Eco-friendly Transportation, Luxury and Leisure Items, Personal Care Products, Electronic Toothbrushes and Clothing and Apparel
match well enough but not exactly to our initial prompt of:
vehicle, clothing, toiletries, food.
As we chose 5 clusters, it split up toiletries into Skincare and Personal Care which doesn't affect us too much further downstream.
selected_examples = df.groupby('Cluster').apply(lambda x: x.sample(3)).reset_index(drop=True)# Format the selected examplesformatted_examples ="\n".join(f'Input: "{row["Product"]}, {row["Category"]}"\nOutput: "{row["Description"]}"\nCluster: "{row["Cluster"]}"'for _, row in selected_examples.iterrows())topic_prompt =f""" I previously generated some examples of input output trainings pairs and then I clustered them based on category. From each cluster I picked 3 example data point which you can find below. I want you identify the broad topic areas these clusters belong to. Previous examples:{formatted_examples} Your output should be strictly of the format: Cluster: number, topic: topic Cluster: number, topic: topic Cluster: number, topic: topic Do not add any extra characters around that formatting as it will make the output parsing break. """response = client.chat.completions.create(model=datagen_model,messages=[ {"role": "system", "content": "You are a helpful assistant designed analyze clustered data"}, {"role": "user", "content": topic_prompt} ])res = response.choices[0].message.contentpattern =r"Cluster: (\d+), topic: ([^\n]+)"matches = re.findall(pattern, res)clusters = [{"cluster": int(cluster), "topic": topic} for cluster, topic in matches]json_output = json.dumps(clusters, indent=2)print(json_output)
We now have the clusters and their counts so we could prompt the LLM to generate more examples within the topics we want. However for this example we won't take that further as they are well-split and you would just follow the procedure above for prompting the model to generate data while passing in the underrepresented topics.
Next, we will try and deal with increasing the diversity of our data distribution.
First we start in a similar way by finding a few examples from each cluster at random and ask the LLM what topics these map to. In addition to this in the same LLM call, we will ask it to generate more topics to increase the diversity of our data. We do this in one call to save time/cost.
selected_examples = df.groupby('Cluster').apply(lambda x: x.sample(3)).reset_index(drop=True)# Format the selected examplesformatted_examples ="\n".join(f'Input: "{row["Product"]}, {row["Category"]}"\nOutput: "{row["Description"]}"\nCluster: "{row["Cluster"]}"'for _, row in selected_examples.iterrows())topic_prompt =f""" I previously generated some examples of input output trainings pairs and then I clustered them based on category. From each cluster I picked 3 example data point which you can find below. I want to promote diversity in my examples across categories so follow the procedure below: 1. You must identify the broad topic areas these clusters belong to. 2. You should generate further topic areas which don't exist so I can generate data within these topics to improve diversity. Previous examples:{formatted_examples} Your output should be strictly of the format: 1. Cluster topic mapping Cluster: number, topic: topic Cluster: number, topic: topic Cluster: number, topic: topic 2. New topics 1. topic 2. topic 3. topic 4. topic Do not add any extra characters around that formatting as it will make the output parsing break. It is very important you stick to that output format """response = client.chat.completions.create(model=datagen_model,messages=[ {"role": "system", "content": "You are a helpful assistant designed to analyze clustered data"}, {"role": "user", "content": topic_prompt} ])res = response.choices[0].message.contentprint(res)
1. Cluster topic mapping
Cluster: 0, topic: Electronic/Health Products
Cluster: 1, topic: Fashion and Food
Cluster: 2, topic: Personal Care/Wellness
Cluster: 3, topic: Eco-friendly Transportation
Cluster: 4, topic: Chocolate/Motorcycles
2. New topics
1. Home Automation Gadgets
2. Educational Tools and Apps
3. Renewable Energy Solutions
4. Virtual Reality Experiences
We can see here again that we explicitly prompt the output structure it should follow. I also tell it the purpose of generating topics (to promote diversity) so the model has full context.
We then parse the data into a list of cluster-mapping jsons and a list of topics
parts = res.split("\n\n")cluster_mapping_part = parts[0]new_topics_part = parts[1]# Parse cluster topic mappingcluster_topic_mapping_lines = cluster_mapping_part.split("\n")[1:] # Skip the first two linescluster_topic_mapping = [{"cluster": int(line.split(",")[0].split(":")[1].strip()), "topic": line.split(":")[2].strip()} for line in cluster_topic_mapping_lines]# Parse new topicsnew_topics_lines = new_topics_part.split("\n")[1:] # Skip the first linenew_topics = [line.split(". ")[1] for line in new_topics_lines]cluster_topic_mapping, new_topics
And finally we can use this information to further prompt a model to keep generating synthetic data. We do this by passing all the topics in the list of jsons to the prompt below.
output_string =""for i inrange(3): question =f""" I am creating input output training pairs to fine tune my gpt model. I want the input to be product name and category and output to be description. the category should be things like: mobile phones, shoes, headphones, laptop, electronic toothbrush, etc. and also more importantly the categories should come under some main topics: {[entry['topic'] for entry in cluster_topic_mapping]}) After the number of each example also state the topic area. The format should be of the form: 1. topic_area Input: product_name, category Output: description Do not add any extra characters around that formatting as it will make the output parsing break. Here are some helpful examples so you get the style of output correct. 1) clothing Input: "Shoe Name, Shoes" Output: "Experience unparalleled comfort. These shoes feature a blend of modern style and the traditional superior cushioning, perfect for those always on the move." """ response = client.chat.completions.create(model="gpt-4",messages=[ {"role": "system", "content": "You are a helpful assistant designed to generate synthetic data."}, {"role": "user", "content": question} ] ) res = response.choices[0].message.content output_string += res +"\n"+"\n"print(output_string)
You can run this in a loop to append to your previous data and in this way you can keep generating more textual synthetic data to train another GPT model while making sure that we cater to imbalanced datasets and generating a diversity of data.
You have now completed part 1 of the synthetic data generation tutorial where we have gone through:
CSV with a structured prompt
CSV with a Python program
Multitable CSV with a python program
Simply creating textual data
Dealing with imbalanced or non-diverse textual data
In part 2 you will find find out techniques for better prompting an LLM to enhance textual synthetic data generation.